

Research in artificial intelligence is progressing at an impressive pace today. More and more industry players now expect to see the arrival of the first artificial general intelligence (AGI), with reasoning abilities superior to those of humans, within a few years. This prospect is as exciting as it is worrying, and for good reason: experts have long believed that such a system could sow unprecedented discord in our civilization.
This is a theme that has often been explored by fiction authors in works such as 2001: A Space Odyssey, Terminator, and The Matrix, to name a few. But as striking as these scenarios may be, they are obviously still rather exaggerated.
If a highly advanced artificial intelligence one day begins to cause harm to humanity, it could also do so in more subtle and less extreme ways. To avoid a potential catastrophe, a solid set of guidelines must be established now. And that's precisely the subject of the latest DeepMind technical paper, spotted by Ars Technica.
For those unfamiliar, this Google subsidiary is one of the most advanced companies in the industry. From game theory (AlphaZero, AlphaGo, etc.) to structural biology (AlphaFold), weather forecasting (GenCast) and nuclear fusion, it has developed numerous AI-based systems to tackle problems that once seemed completely unattainable.
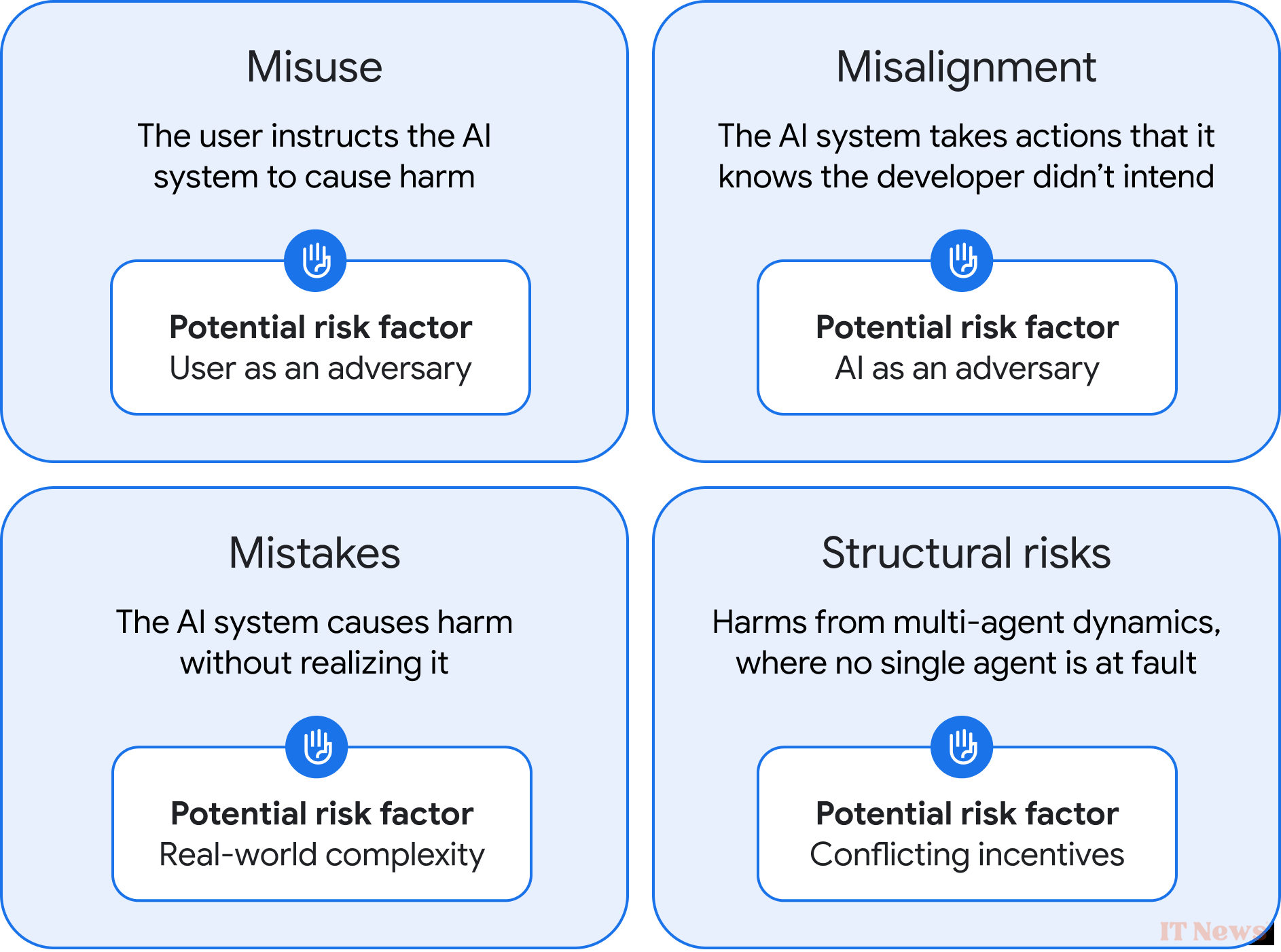
Recently, its researchers published a long paper that explores different approaches to limiting the risks associated with the development of an AGI. It focuses in particular on the different types of risks associated with such a system. In total, the authors identified four broad categories.
A weapon for ill-intentioned humans
The first concerns what DeepMind describes as "abuse ." In this case, it is not the system itself that is directly problematic, but the humans who control it. It seems clear that a tool as powerful as an AGI could cause significant damage if it fell into the hands of malicious actors. For example, they could ask it to exploit critical cybersecurity vulnerabilities, particularly in critical infrastructure such as nuclear power plants, to create formidable bacteriological weapons, and so on.
DeepMind therefore believes that companies must implement extremely robust validation and security protocols, starting now. The authors also emphasize the importance of developing techniques that force AI models to “forget” data, so that they can be pulled out of their boots in an emergency if a worst-case scenario begins to loom.
Machine learning: why AI absolutely must learn to forget
Alignment errors
The second category encompasses all the problems related to what is called alignment—ensuring that these AI models “understand” human values and expectations, and prioritize them when acting. A poorly aligned system, on the other hand, might therefore take actions that it knows perfectly well do not match the creator’s vision.
This is the most common scenario in fiction. For example, if HAL 9000 attempts to eliminate the ship's crew in 2001: A Space Odyssey, it's because he considers the success of the mission to be more valuable than human life. The same goes for Skynet in the Terminator saga: while it was initially designed to defend humanity, it ultimately concluded that it was a threat that deserved to be eradicated at all costs.

To avoid this kind of scenario, DeepMind offers an interesting first solution: having AGIs work in pairs. Instead of evolving on their own, they would be constantly supervised by a strictly identical clone, thus reducing the risk of drift. But the authors of the paper acknowledge that this approach would probably be far from infallible.
At the same time, they therefore recommend running future AGIs in “virtual sandboxes.” This term refers to digital spaces isolated from the rest of the system, which are currently mainly used in the field of cybersecurity to test sensitive programs without risking compromising the rest of the infrastructure. In theory, if a problem arises, simply deactivating this sandbox would deprive the AGI of its ability to cause harm. However, one might wonder if such a cunning system could find a way to escape…
When AI Loses Its Mind
The third category, titled “Errors,” may seem quite similar to alignment problems. But it does rely on a crucial distinction: here, the AI model is unaware of the harmful consequences of its actions. It thinks it's doing the right thing when it's completely off the mark, as when Google's AI Overview feature recommended that people put glue on their pizzas to prevent melted cheese from sliding around.
This example may seem funny, but it's easy to imagine situations where such errors (sometimes called hallucinations) could have dire consequences. Imagine, for example, that a military-oriented AI thinks it detects the warning signs of a nuclear strike; it could then trigger a completely unjustified "retaliation," leading to the total annihilation of a part of the globe based on a simple mistake.
The bad news is that there isn't really a generalized approach to mitigating these errors. For the authors of the paper, it will therefore be crucial to deploy future AGIs gradually, with rigorous testing at each stage, and above all to limit their ability to act autonomously.
Large-scale structural risks
The last category, and perhaps the most interesting, brings together what DeepMind calls “structural risks.” Here, the problem would not emerge from a single isolated system, but from the interactions between several complex systems integrated at different levels of our society.
Together, these interactive systems could “accumulate increasing control over our economic and political systems,” over the flow of information, and so on. In other words, AGI would eventually take control of our entire society, while humans would become nothing more than insignificant organic pawns on a vast virtual chessboard. A dystopian scenario that is decidedly chilling.
The researchers point out that this category of risk will undoubtedly be the most difficult to counter, because the potential consequences depend directly on how people, infrastructures, and institutions operate and interact.
At present, no one knows exactly when—or even if—a true AGI will actually emerge. But in the current context, it would be foolhardy not to take this possibility seriously. It will therefore be interesting to see if OpenAI and others base their future work on this admittedly abstract, but nonetheless very interesting, paper.






0 Comments